Intro
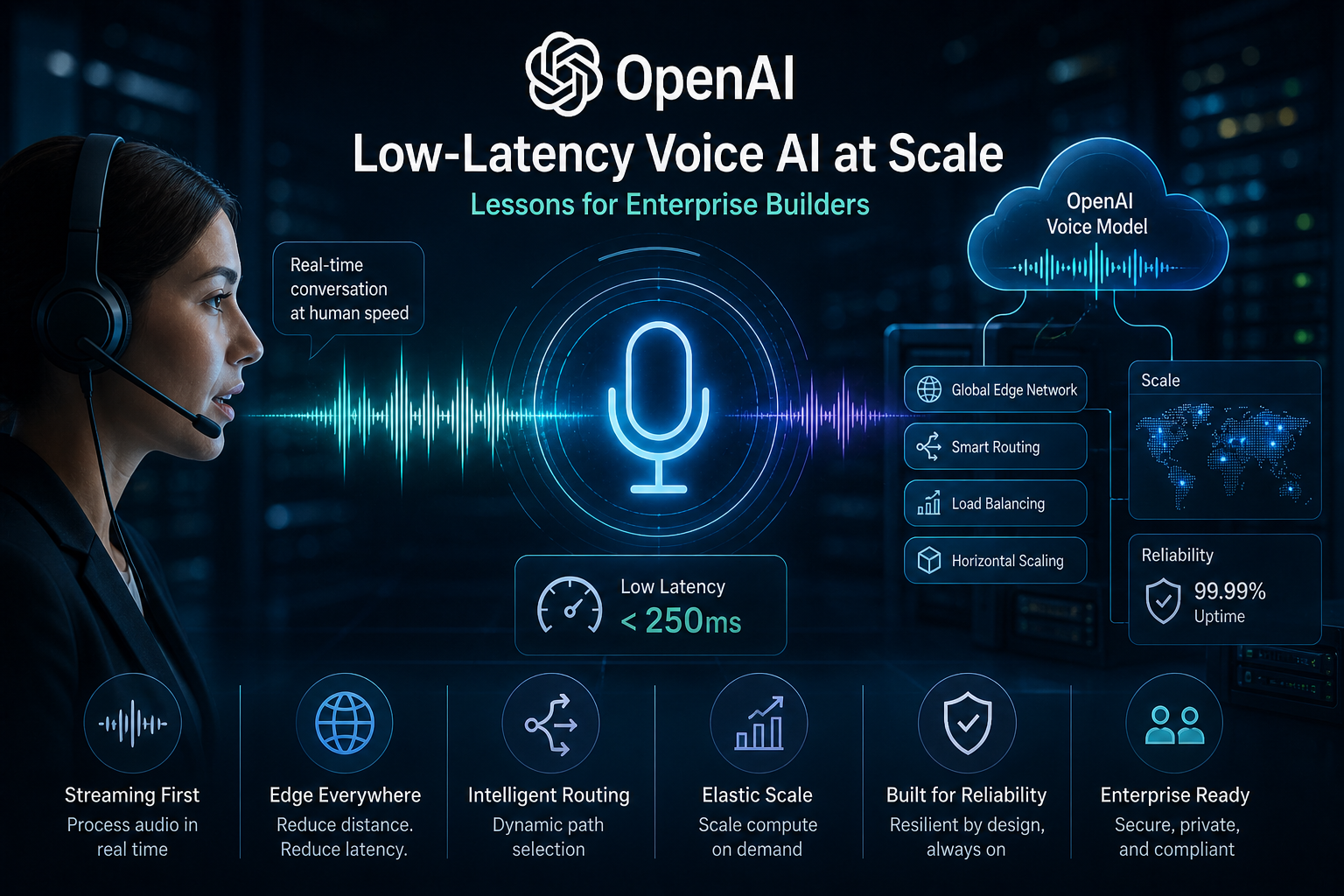
Voice AI is no longer just a novelty—it’s becoming a core part of enterprise applications, from customer service bots to real-time collaboration tools. OpenAI’s recent engineering deep dive on delivering low-latency voice AI at scale reveals the infrastructure work needed to make these systems feel natural. As someone who’s seen voice projects stall on latency issues, this is a must-read for anyone building or scaling AI-driven interactions.
What happened
On May 4, 2026, OpenAI published a blog post detailing how they achieve sub-300ms response times for voice AI, even at massive scale. They rearchitected their WebRTC stack to handle global routing, stateful sessions, and efficient packet handling. Key innovations include a split relay architecture, native speech-to-speech models that bypass traditional STT-LLM-TTS pipelines, and advanced voice activity detection for natural turn-taking. This powers their Realtime API, enabling seamless voice interactions without the awkward pauses that plague many systems.
Why it matters
Low-latency voice AI opens up new commercial opportunities in sectors like customer support, telehealth, and collaborative work. For enterprises, it means AI can handle real-time conversations without frustrating users, reducing drop-off rates and improving satisfaction. Operationally, it lowers the bar for deploying voice features, potentially cutting costs on custom infrastructure while boosting adoption. In a world where AI is expected to feel human-like, this sets a new standard for responsiveness.
Who should care
AI architects and engineering leaders building voice-enabled applications; operators scaling AI services in high-demand environments; consultants advising on enterprise AI adoption. If you’re dealing with real-time AI, this is your blueprint.
What most people are missing
The post isn’t just about models—it’s the deep infrastructure engineering that makes it work. Many overlook how WebRTC limitations can bottleneck scale, or how native audio processing preserves tone and emotion that text pipelines lose. OpenAI’s approach to interruptions and streaming output is a game-changer for natural flow, something generic setups often fumble.
What to do next
- Evaluate OpenAI’s Realtime API for your voice prototypes—test latency in real scenarios.
- Audit your WebRTC setup for similar optimizations, like global routing and VAD tuning.
- Consider speech-to-speech models for new projects to avoid pipeline overhead.
- Run benchmarks: Aim for <300ms end-to-end latency as your North Star.
Bottom line
OpenAI’s work demystifies low-latency voice AI, proving it’s achievable at scale with smart engineering. For enterprise teams, this is a call to prioritize infrastructure alongside models—get it right, and voice AI becomes a competitive edge, not a headache.